条款 41:了解隐式接口和编译期多态。
描述引入template带来的变化,在template世界中,多态会前移到编译阶段。
请记住
- classes和templates都支持接口和多态。
- 对classes而言接口是显示的,以函数签名为中心。多态则是通过virtual函数发生于运行期。
- 对template参数而言,接口是隐式的,奠基于有效表达式。多态则是通过template具现化和函数重载解析发生于编译期。
条款 42:了解 typename 的双重意义。
在template声明中:
template<class T> class Widget;
template<typename T> class Widget;这两种声明式并无不同。
在继续往下看之前,需要先理解模板中的一个重要概念从属名称和嵌套性。
在 C++ 模板中,名称的 “依赖性” 是编译器解析模板代码的核心问题。根据名称是否依赖模板参数、以及是否嵌套在依赖类型内部,可明确区分嵌套从属名称和非嵌套从属名称。理解这两个概念是掌握模板语法(尤其是typename关键字用法)的关键。
(1)基础类型:从属名称 vs 非从属名称
在区分 “嵌套” 与 “非嵌套” 之前,需先明确 “从属” 与 “非从属” 的定义:
非从属名称(non-dependent names)
名称的含义与模板参数无关,在模板定义时就能确定。
例:int、std::string、global_var(全局变量)、foo()(非模板函数)等。
编译器在解析模板定义时,可直接检查这类名称的合法性。
从属名称(dependent names)
名称的含义依赖于模板参数,只有在模板实例化时(知道参数具体类型)才能确定。
例:若T是模板参数,则T(模板参数本身)、T::member(T的成员)、T*(T的指针)等都属于从属名称。
(2) 嵌套从属名称(nested dependent names)
嵌套从属名称是一种特殊的从属名称:它是嵌套在 “从属类型” 内部的名称。
通俗说:如果X是一个依赖于模板参数的类型(即X是 “从属类型”),那么X::Y就是嵌套从属名称(Y是X内部的成员名称)。
template<typename T>
void func() {
// 1. "T::iterator" 是嵌套从属名称
// - T是模板参数(从属类型,依赖于模板参数)
// - iterator是T内部的名称,其含义随T变化(可能是类型、变量或函数)
T::iterator it;
// 2. "typename T::value_type" 也是嵌套从属名称
// (需用typename声明其为类型,见后文解释)
typename T::value_type val;
}这里的T::iterator和T::value_type都是嵌套从属名称 —— 它们依赖于T的具体类型(比如T是std::vector<int>时,T::iterator是迭代器类型;若T是自定义类,iterator可能是成员变量)。
(3) 非嵌套从属名称(non-nested dependent names)
非嵌套从属名称是依赖于模板参数,但不嵌套在其他从属类型内部的名称。
它们依赖模板参数,但本身是 “独立” 的(不是某个从属类型的内部成员)。
template<typename T>
void func(T obj) {
// 1. "T" 是从属名称(依赖模板参数),但非嵌套(T本身是模板参数,不是某个类型的内部成员)
T new_obj;
// 2. "obj" 是T类型的对象(依赖T),但不是嵌套在其他从属类型内部的名称
obj.do_something();
// 3. "T*" 是从属名称(依赖T),但非嵌套(指针类型由T直接构成,不涉及T的内部成员)
T* ptr;
}这些名称依赖于T,但不属于 “某个从属类型的内部成员”,因此是非嵌套从属名称。
(4) 为什么要区分?--编译器的“二义性困境”
C++ 模板解析分两个阶段:
- 定义时:检查非从属名称的语法(已知其含义)。
- 实例化时:结合具体模板参数,检查从属名称的合法性。
对于嵌套从属名称,编译器在 “定义时” 无法判断它是 “类型” 还是 “非类型”(如成员变量、函数),从而产生歧义。
歧义示例:
template<typename T>
void func() {
T::iterator * p; // 歧义!
}- 若
T::iterator是类型:这是 “定义一个T::iterator类型的指针p”。 - 若
T::iterator是静态成员变量:这是 “T::iterator乘以p” 的表达式。
(5) 解决歧义:typename关键字的作用
为告诉编译器 “某个嵌套从属名称是类型”,必须在其前添加typename关键字(少数例外场景除外)。
template<typename T>
void func() {
// 正确:用typename声明"T::iterator"是类型
typename T::iterator it;
// 正确:声明"T::value_type"是类型
typename T::value_type val = 0;
}无需typename的例外场景:
在以下场景中,嵌套从属名称默认被视为类型,无需加typename:
基类列表中(声明继承关系时):
template<typename T>
class Derived : public T::Base { // T::Base是基类,默认视为类型
};成员初始化列表中(初始化基类或成员时):
template<typename T>
class Derived : public T::Base {
public:
Derived() : T::Base() {} // 初始化基类,T::Base视为类型
};总结:
| 名称类型 | 定义 | 处理方式 |
|---|---|---|
| 非从属名称 | 不依赖模板参数,含义固定 | 定义时解析,无需额外关键字 |
| 非嵌套从属名称 | 依赖模板参数,但非从属类型的内部成员 | 实例化时解析,无需typename |
| 嵌套从属名称 | 依赖模板参数,且是从属类型的内部成员 | 需用typename声明为类型(例外场景除外) |
理解这两种名称的关键是:嵌套从属名称因 “嵌套在从属类型内部” 而存在歧义,必须用typename明确其为类型。这是模板编程中避免编译错误的基础技巧。
当类型很长时,通常使用如下的typedef预先定义的方式简化语句:
template<typename IterT>
void workWithIterator(IterT iter)
{
typedef typename std::iterator_traits<IterT>::value_type value_type;
value_type temp(*iter);
}请记住
- 声明template参数时,前缀关键字class和typename可互换。
- 请使用关键字typename标识嵌套从属类型名称;但不得在base class lists(基类列)或member initialization list(成员初值列)内以它作为base class修饰符。
条款 43:学习处理模板化基类的名称。
本例中讲解的示例可以参考下面的类图展示:
@startuml
class CompanyA {
+ SendClearText(msg: const string&): void
+ SendEncrypted(msg: const string&): void
}
class CompanyB {
+ SendClearText(msg: const string&): void
+ SendEncrypted(msg: const string&): void
}
class CompanyZ {
+ SendClearText(msg: const string&): void
+ SendEncrypted(msg: const string&): void
}
class MsgInfo {
- content: string
- timestamp: long
}
note top of MsgInfo
用来保存信息(包含内容和时间戳)
end note
' 主模板类:参数为Company(公司类型)
class "MsgSender<Company>" as MsgSender {
+ SendClear(info: const MsgInfo&): void
+ SendSecret(info: const MsgInfo&): void
}
note top of MsgSender
发送信息模板类,根据不同Company实现发送逻辑
end note
' 继承自模板类的日志增强类(模板参数保持一致)
class "LoggingMsgSender<Company>" as LoggingMsgSender {
+ sendClearMsg(info: const MsgInfo&): void
}
LoggingMsgSender--|>MsgSender: 继承(增强日志功能)
note right of LoggingMsgSender
使用this->SendClear(info)
或using声明引入基类接口
endnote
' CompanyZ的全特化类
class "MsgSender<CompanyZ>" as CompanyZMsgSender {
+ sendSecret(info: const MsgInfo&): void
}
note top of CompanyZMsgSender
对CompanyZ的全特化实现,只支持sendSecret逻辑
end note
CompanyZMsgSender--|>MsgSender: 全特化(针对CompanyZ)
' 关联关系修正:明确"使用"或"发送到"的语义
MsgSender-->MsgInfo: 使用(作为发送数据)
MsgSender-->CompanyA: 发送到(公司A)
MsgSender-->CompanyB: 发送到(公司B)
MsgSender-->CompanyZ: 发送到(公司Z)
@enduml
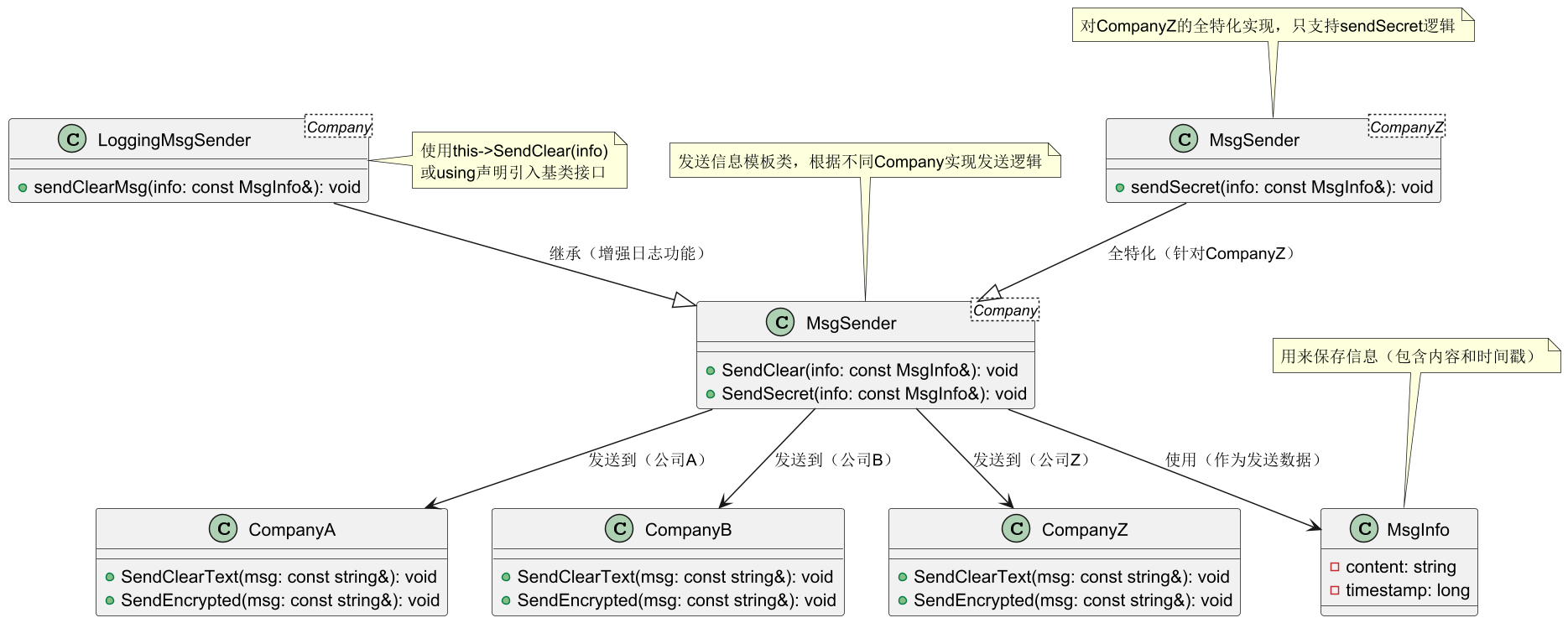
本问题主要在于当类的继承跨进Template C++之后,继承将不再像以前那样畅通无阻,正如这里的MsgSender对ComanyZ的特化一样,特化后的模板处理只支持sendSecret,那么当LoggingMsgSender中SendClearMsg调用父类模板中的SendClear时会失败,因为模板不支持此函数。
核心问题是模板化基类中的名称在派生类模板中默认不可见,这导致编译器在编译派生类时无法解析基类成员。
以下是相应的代码示例和解决方式:
// 公司类(示例)
class CompanyA {
public:
void SendClearText(const std::string& msg); // 发送明文
void SendEncrypted(const std::string& msg); // 发送密文
};
class CompanyZ {
public:
void SendEncrypted(const std::string& msg); // 仅支持密文
};
// 消息信息类
class MsgInfo { /* 保存消息内容、时间戳等 */ };
// 模板化基类:根据不同公司发送消息
template<typename Company>
class MsgSender {
public:
void SendClear(const MsgInfo& info) {
std::string msg = /* 生成明文 */;
Company c;
c.SendClearText(msg); // 调用公司的明文发送接口
}
void SendSecret(const MsgInfo& info) { /* 发送密文 */ }
};派生类的问题代码:
// 派生类模板:增强日志功能
template<typename Company>
class LoggingMsgSender : public MsgSender<Company> {
public:
void sendClearMsg(const MsgInfo& info) {
Log("Before sending clear message");
SendClear(info); // ❌ 编译错误:无法解析SendClear
Log("After sending clear message");
}
};特化基类导致的问题:
// 针对CompanyZ的特化(删除SendClear)
template<>
class MsgSender<CompanyZ> {
public:
void SendSecret(const MsgInfo& info) { /* 仅支持密文 */ }
};
// 使用特化基类时的错误
LoggingMsgSender<CompanyZ> zSender;
MsgInfo data;
zSender.sendClearMsg(data); // ❌ 编译错误:CompanyZ的基类没有SendClear问题根因:
- 两阶段查找机制:
- 阶段一(模板定义期):编译器解析派生类模板时,基类模板是未实例化的 “不完全类型”,无法确定其成员。
- 阶段二(模板实例化期):只有在实例化时,编译器才知道基类的具体类型和成员。
- 模板特化的风险:
基类模板可能被特化(如MsgSender<CompanyZ>),导致接口与通用模板不一致。编译器默认假设特化可能改变接口,因此拒绝隐式查找基类成员。
解决方式:
方案 1:使用this->显式调用基类成员
template<typename Company>
class LoggingMsgSender : public MsgSender<Company> {
public:
void sendClearMsg(const MsgInfo& info) {
Log("Before sending clear message");
this->SendClear(info); // ✅ 通过this->明确调用基类成员
Log("After sending clear message");
}
};方案 2:使用using声明引入基类成员
template<typename Company>
class LoggingMsgSender : public MsgSender<Company> {
public:
using MsgSender<Company>::SendClear; // ✅ 将基类成员引入作用域
void sendClearMsg(const MsgInfo& info) {
Log("Before sending clear message");
SendClear(info); // 直接调用已引入的基类成员
Log("After sending clear message");
}
};方式3:显示基类限定(慎用)
template<typename Company>
class LoggingMsgSender : public MsgSender<Company> {
public:
void sendClearMsg(const MsgInfo& info) {
Log("Before sending clear message");
MsgSender<Company>::SendClear(info); // ✅ 显式指定基类作用域
Log("After sending clear message");
}
};注意:方案 3 会关闭虚函数的动态绑定(若SendClear是虚函数),因此仅适用于非虚成员。
解决方案对比与选择:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
this-> |
保持多态行为,代码简洁 | 需每个调用处添加this-> |
频繁调用基类成员 |
using声明 |
一次性引入所有基类成员,代码清晰 | 可能引入不需要的成员 | 需批量引入基类接口 |
| 显式基类限定 | 明确作用域,避免名称冲突 | 关闭虚函数绑定,代码冗长 | 静态成员或非虚函数调用 |
请记住
可在derived class template内通过“this->"指涉base class templates内的成员名称,或藉由一个明白写出的”base class资格修饰符“完成。
条款 44:将与参数无关的代码抽离 templates。
这个条款初看有些难以理解,其核心问题实际在于模板实例化导致的代码膨胀:当模板中包含与参数无关的代码时,编译器会为每个模板实例生成重复的代码副本。
书中的问题场景:
// 固定大小的方阵模板(矩阵大小n为非类型模板参数)
template<typename T, std::size_t n>
class SquareMatrix {
public:
void invert(); // 求矩阵的逆
// ... 其他成员(如operator[]、print等)
};
// 使用示例
SquareMatrix<double, 5> matrix5; // 5x5矩阵
matrix5.invert(); // 调用SquareMatrix<double,5>::invert
SquareMatrix<double, 10> matrix10; // 10x10矩阵
matrix10.invert(); // 调用SquareMatrix<double,10>::invert-
问题根源:虽然
invert函数的算法逻辑完全相同,但矩阵大小n作为模板参数,导致编译器为每个n生成独立的invert副本。 -
实际影响
- 二进制文件体积膨胀(两个
invert函数代码几乎重复)。 - 编译时间增加(每个模板实例都需重新编译)。
- 维护成本上升(修改算法需同时更新所有实例)。
可以用如下更通俗的语言描述:
类比:不同尺寸的盒子工厂
假设你经营一家生产不同尺寸盒子的工厂:
-
模板参数:盒子的尺寸(如 5cm×5cm、10cm×10cm)。
-
模板代码:生产盒子的流程(切割纸板、折叠、粘贴)。
-
问题
:每个尺寸的盒子都需要一套独立的生产流程,即使流程完全相同,只是尺寸不同。这导致:
- 工厂需要重复购买相同的设备(代码冗余)。
- 生产效率低下(编译时间长)。
- 升级设备时需逐个调整(维护困难)。
解决方案:标准化生产流程
- 核心思路:将与尺寸无关的通用流程(如切割、折叠)提取到公共设备中,仅在生产时传入具体尺寸参数。
- 具体实现
- 建造一台通用机器(基类),接受尺寸参数并执行通用流程。
- 不同尺寸的盒子工厂(派生类)只需调用通用机器,无需重复建设。
优化的方式就是使用基类结合private继承:
// 基类:存储矩阵数据指针和大小,实现通用算法 templateclass SquareMatrixBase { protected: SquareMatrixBase(std::size_t _n, T* _data) : n(_n), data(_data) {} void invert(std::size_t matrixSize) { // 通用求逆算法(与T无关,仅依赖matrixSize) for (std::size_t i = 0; i < matrixSize; ++i) { // ... 矩阵求逆的核心逻辑 ... } } std::size_t n; T* data; }; // 派生类:继承基类,提供具体数据存储 template class SquareMatrix : private SquareMatrixBase { public: SquareMatrix() : SquareMatrixBase (n, data) {} // 初始化基类 void invert() { this->invert(n); // 调用基类的invert,传递当前矩阵大小n } private: T data[n * n]; // 存储矩阵数据 }; - 消除重复代码:无论
n是 5 还是 10,invert函数的核心逻辑仅在基类中存在一份。 - 编译效率提升:编译器只需编译一次基类代码,派生类仅生成少量粘合代码。
- 维护方便:修改求逆算法时,只需更新基类即可影响所有派生类。
关键点说明:
- 私有继承的作用
SquareMatrix私有继承SquareMatrixBase,表示 “基类是实现细节”,而非 “is-a” 关系(条款 39)。- 基类的
invert方法声明为protected,避免外部直接调用。
- this-> 的使用
- 在派生类中调用基类成员时,使用
this->避免名称隐藏(条款 43)。 - 例如:
this->invert(n)明确调用基类的invert方法。
- 非类型参数的处理
- 原模板中的
n作为非类型参数,导致代码膨胀。 - 解决方案将
n作为参数传递给基类的invert方法,而非模板参数,从而消除膨胀。
- 二进制文件体积膨胀(两个
条款 45:运用成员函数模板接受所有兼容类型。
对于本条款,先要明确概念,什么是成员函数模板(member function template)?这里给出一个例子进行说明:
template<class T> // 类模板参数
class MyClass {
public:
template<class Y> // 成员函数模板参数
void func(Y arg); // 成员函数模板
};- 类本身是模板(带参数
T); - 类的成员函数也是模板(带参数
Y); - 成员函数的模板参数
Y可以独立于类的模板参数T,但通常会与T存在某种关联(比如兼容的类型)。
下面需要回答为什么需要使用成员函数模板进行类型兼容。
先来看下为什么要用成员函数模板,书中以shared_ptr为例。
shared_ptr是 C++ 智能指针中用于 “共享所有权” 的类型,其核心功能之一是支持多态类型的安全管理(比如用shared_ptr<Base>管理Derived*指针)。要实现这一点,就必须解决一个问题:如何让shared_ptr<Base>能从Derived*构造,同时保证类型安全?
1. 不使用成员函数模板的痛点
假设shared_ptr的构造函数不是模板,而是普通函数:
template<class T>
class shared_ptr {
public:
explicit shared_ptr(T* p); // 非模板构造函数:只能接受T*
};此时,如果有继承关系:
class Base {};
class Derived : public Base {};我们希望用Derived*构造shared_ptr<Base>(因为Derived是Base的派生类,指针可以向上转换):
Derived* d = new Derived();
shared_ptr<Base> p(d); // 期望:成功构造(Derived* → Base* 是合法转换)但上述代码会编译失败。因为shared_ptr<Base>的构造函数只接受Base*,而d是Derived*—— 即使Derived*可以隐式转换为Base*,但编译器不会自动将shared_ptr<Base>的构造函数参数从T*(Base*)“适配” 为Derived*。
2.用成员函数模板解决问题
shared_ptr的解决方案是定义模板构造函数,让构造函数的参数类型Y*可以独立于类的模板参数T,但要求Y*能转换为T*(即Y是T的派生类):
template<class T>
class shared_ptr {
public:
// 成员函数模板:接受任意Y*,只要Y*能转换为T*
template<class Y>
explicit shared_ptr(Y* p); // 用Y*构造shared_ptr<T>
};此时,用Derived*构造shared_ptr<Base>就会成功:
Derived* d = new Derived();
shared_ptr<Base> p(d); // 成功:Y=Derived,T=Base,Derived*可转换为Base*因为模板构造函数shared_ptr<Base>::shared_ptr<Derived>(Derived* p)会被实例化,而Derived*到Base*的转换是合法的,因此构造成功。
成员函数模板的本质是为类生成一系列 “类型兼容” 的成员函数版本,而无需手动为每个兼容类型编写重载函数。
举例:容器的 “拷贝构造” 与 “转换构造”
除了智能指针,容器类也常用成员函数模板处理 “从其他兼容容器构造” 的场景。比如vector的模板构造函数:
template<class T>
class vector {
public:
// 模板构造函数:从“元素类型为Y”的vector构造当前vector(要求Y可转换为T)
template<class Y>
vector(const vector<Y>& other); // 例如:vector<double> → vector<int>(如果double可转int)
};如果没有这个模板构造函数,我们需要为每个可能的Y(如double、float等)手动编写vector<int>的构造函数,这显然不现实。成员函数模板通过 “泛化” 自动生成这些版本,极大减少了代码冗余。
注意事项:成员函数模板不会替代默认函数
成员函数模板不会抑制编译器生成默认函数(如默认构造、拷贝构造、析构等)。例如:
template<class T>
class MyClass {
public:
// 模板构造函数
template<class Y>
MyClass(Y* p);
// 编译器仍会生成默认拷贝构造函数:MyClass(const MyClass&)
};如果需要自定义拷贝构造函数,必须显式定义(不能仅靠模板构造函数替代)。比如shared_ptr的拷贝构造函数需要单独处理 “引用计数” 的复制,因此除了模板构造函数,还会有专门的拷贝构造:
template<class T>
class shared_ptr {
public:
// 模板构造函数(从Y*构造)
template<class Y>
explicit shared_ptr(Y* p);
// 专门的拷贝构造函数(同类型拷贝)
shared_ptr(const shared_ptr& other);
// 模板拷贝构造函数(从shared_ptr<Y>拷贝,Y可转换为T)
template<class Y>
shared_ptr(const shared_ptr<Y>& other);
};总结
条款 45 的核心是:当需要接受 “所有兼容类型” 作为参数时,优先使用成员函数模板,而非手动编写大量重载函数。其优势在于:
- 减少代码冗余:无需为每个兼容类型写重载;
- 自动适配类型:只要类型兼容(如派生类→基类),自动生成对应版本;
- 保持类型安全:编译器会检查
Y与T的兼容性,拒绝不合法转换(如Base*→Derived*的向下转换,除非显式允许)。
生活化例子阐述
场景设定:你是一家手机店的店员,需要给不同品牌的手机充电
- 你的任务:用店里的 “通用充电底座” 给各种手机充电,但底座的接口是固定的(比如 “安卓 Type-C 接口”)。
- 遇到的问题:顾客带来的手机品牌不同(华为、小米、OPPO),但它们的充电接口都是 “安卓 Type-C”(兼容底座);但如果来了个苹果手机(Lightning 接口,不兼容),就不能充。
对应到C++的概念:
| 现实场景 | C++ 代码概念 | 具体说明 |
|---|---|---|
| 你的 “通用充电底座” | 类模板 shared_ptr<T> |
底座的 “接口类型” 是固定的(比如T=Base,代表 “安卓 Type-C 接口标准”)。 |
| 底座的 “充电功能” | shared_ptr<T> 的构造函数 |
作用是 “把电充进去”(把指针 “托管” 进来)。 |
| 顾客的手机 | 指针类型 Y* |
比如Y=Derived(华为手机,符合安卓 Type-C 标准)、Y=OtherAndroid(小米手机)。 |
| 手机的 “充电接口” | Y 与 T 的兼容性 |
华为、小米的接口都兼容安卓 Type-C(Derived是Base的派生类,Y*可转T*)。 |
| 你的 “万能充电插头” | 成员函数模板 shared_ptr(Y* p) |
这个插头能适配所有 “接口兼容的手机”(只要Y*能转T*,就能构造shared_ptr<T>)。 |
| 苹果手机(接口不兼容) | 不兼容的 Y*(如Y=Unrelated) |
插头插不进底座(编译器报错,拒绝构造)。 |
为什么需要 “成员函数模板”(万能插头)?
假设没有这个万能插头,你只能给 “指定品牌” 的手机充电:
- 要给华为充电,得专门做一个 “华为专用插头”(为
Derived*写一个重载构造函数); - 要给小米充电,再做一个 “小米专用插头”(再为
OtherAndroid*写一个重载); - 一旦来了新品牌的安卓手机,你就得再做一个新插头(代码冗余爆炸)。
而有了 “万能插头”(成员函数模板):
- 只要手机接口符合安卓标准(
Y*能转T*),一个插头全搞定; - 新品牌手机只要兼容标准,无需修改底座(代码),直接能用;
- 苹果手机(不兼容)插不进,避免 “乱充电”(类型安全)。
最后再结合代码查看一下:
// 定义“接口标准”(Base类,类似安卓Type-C标准)
class Base {};
// 华为手机(符合Base标准,Derived是Base的派生类)
class Derived : public Base {};
// 小米手机(也符合Base标准)
class OtherAndroid : public Base {};
// 苹果手机(不符合Base标准,和Base没关系)
class Apple {};
// “通用充电底座”(shared_ptr<T>,T=Base,即安卓标准底座)
template<class T>
class shared_ptr {
public:
// “万能插头”(成员函数模板,接受所有兼容Y*)
template<class Y>
explicit shared_ptr(Y* p) {
// 只有Y*能转成T*(即Y是T的派生类),这里才能正常工作
// 就像只有安卓手机能插进安卓底座
}
};
// 实际使用:
int main() {
Derived* huawei = new Derived();
OtherAndroid* xiaomi = new OtherAndroid();
Apple* iphone = new Apple();
// 华为、小米都能用底座充电(构造成功)
shared_ptr<Base> p1(huawei); // 万能插头适配华为
shared_ptr<Base> p2(xiaomi); // 万能插头适配小米
// 苹果插不进(编译器报错,拒绝构造)
shared_ptr<Base> p3(iphone); // 错误:Y=Apple与T=Base不兼容
}条款 46:需要类型转换时请为模板定义非成员函数。
本条款实际上是描述了在C++ Template这个范畴内的条款24场景的处理方式。大家可以先回看下条款24.
核心问题是模板类的成员函数无法对所有参数进行隐式类型转换,而解决方案是通过 ** 非成员函数(通常结合友元声明)来实现这一需求。以下是具体分析和示例:
一、问题场景:模板类的成员函数无法支持混合类型运算
1. 模板类设计
template<typename T>
class Rational {
public:
Rational(T numerator = 0, T denominator = 1); // 构造函数(非explicit,允许隐式转换)
const Rational<T>& operator* (const Rational<T>& rhs) const; // 成员函数
private:
T numerator; // 分子
T denominator; // 分母
};2. 混合类型运算的问题
Rational<int> oneHalf(1, 2); // 分子1,分母2
Rational<int> result = oneHalf * 2; // ❌ 编译错误:无法将int转换为Rational<int>- 问题根源:
operator*是成员函数,左操作数oneHalf是Rational<int>类型,右操作数2是int类型。 - 编译器行为:
- 成员函数的左操作数必须是类对象(
Rational<int>),无法将2隐式转换为Rational<int>作为左操作数。 - 虽然右操作数
2可以通过构造函数转换为Rational<int>,但编译器在模板实参推导阶段不考虑隐式转换,导致无法匹配函数签名。
- 成员函数的左操作数必须是类对象(
二、解决方案:类内定义友元函数 + 辅助模板函数
1. 核心方案
在类内部定义友元函数,并通过一个辅助模板函数(如doMultiply) 实现具体逻辑,既避免链接问题,又复用代码:
// 辅助模板函数:实现乘法逻辑(可复用)
template<typename U>
const Rational<U> doMultiply(const Rational<U>& lhs, const Rational<U>& rhs);
template<typename T>
class Rational {
public:
Rational(T numerator = 0, T denominator = 1)
: n(numerator), d(denominator) {}
// 友元函数在类内定义(关键!)
friend const Rational operator*(const Rational& lhs, const Rational& rhs) {
// 调用辅助模板函数实现逻辑
return doMultiply(lhs, rhs);
}
private:
T n, d; // 分子、分母
};
// 辅助模板函数的类外定义
template<typename U>
const Rational<U> doMultiply(const Rational<U>& lhs, const Rational<U>& rhs) {
return Rational<U>(lhs.n * rhs.n, lhs.d * rhs.d);
}2. 为什么这样能解决问题?
- 类内定义的友元函数是 “非模板函数”:
当Rational<int>实例化时,编译器会自动生成一个针对int的operator*(非模板),其函数体明确调用doMultiply<int>,避免链接错误。 - 辅助函数
doMultiply是独立模板:
负责实际运算逻辑,可被不同实例化的Rational共享(如Rational<int>和Rational<double>都能调用),避免代码冗余。 - 隐式类型转换正常工作:
非成员函数(友元)允许左右操作数都进行隐式转换,例如:
Rational<int> a(1, 2);
Rational<int> b = a * 3; // 3隐式转换为Rational<int>(3,1),调用operator*成功三、关键细节解析
1. 友元函数的 “非模板” 特性
类内定义的友元函数不是模板函数,而是针对每个Rational<T>实例化的 “专属函数”。例如:
- 当
T=int时,生成operator*(const Rational<int>&, const Rational<int>&); - 当
T=double时,生成operator*(const Rational<double>&, const Rational<double>&)。
这种 “专属函数” 由编译器自动生成,不会出现链接问题。
2. 辅助函数doMultiply的作用
- 分离接口与实现:友元函数仅作为 “接口”,实际逻辑放在
doMultiply中,便于维护; - 模板复用:
doMultiply是独立模板,可被所有Rational<T>实例共享,避免重复编写乘法逻辑。
3. 为什么不直接在友元函数内实现逻辑?
可以直接实现,但书中推荐用辅助函数:
// 也能工作,但不利于代码复用
friend const Rational operator*(const Rational& lhs, const Rational& rhs) {
return Rational(lhs.n * rhs.n, lhs.d * rhs.d);
}使用辅助函数的优势在于:当逻辑复杂时(如分数化简、溢出检查),可在doMultiply中统一实现,所有友元函数共享同一套逻辑。
四、链接错误的本质原因
模板类的友元函数若在类外定义,会陷入 “模板参数依赖” 的矛盾:
- 友元函数的参数类型是
Rational<T>,依赖类模板的T; - 但友元函数自身是独立模板(
template<typename T> operator*),编译器无法确定其T与类模板的T是否一致,导致实例化失败。
而类内定义的友元函数不依赖独立模板参数,直接与当前Rational<T>绑定,因此编译器能正确生成实例。
五、总结
条款 46 的核心解决方案是:在模板类内部定义友元函数,并通过辅助模板函数实现逻辑。这样做的好处是:
- 避免链接错误:类内定义确保每个
Rational<T>实例都有对应的operator*实现; - 支持隐式类型转换:非成员函数允许所有参数参与转换;
- 代码复用:辅助函数
doMultiply统一实现逻辑,降低维护成本。
这正是书中强调的 “友元函数类内定义 + 辅助模板” 的模式,完美解决了模板类中混合类型运算的编译和链接问题。
条款 47:请使用 traits classes 表现类型信息。
如果要读懂这个条款需要先了解一些基础内容。traits实际上阐述了为什么STL能够处理不同的类型。
一、先搞懂:什么是 STL 迭代器?为什么要分类?
1. 迭代器的本质:“容器的指针”
你可以把迭代器想象成 “容器专用的指针”。比如:
- 遍历
vector(动态数组)时,迭代器像int*指针,能直接访问任意元素(it + 5); - 遍历
list(链表)时,迭代器像 “链表节点的指针”,只能一步一步挪(++it或--it),不能跳步。
迭代器的作用:让我们用统一的方式(++it、*it)遍历不同容器,不用关心容器内部结构(数组、链表、树等)。
2. 为什么要给迭代器分类?
不同容器的 “物理结构” 差异很大,导致迭代器能做的操作也不同:
vector是连续内存(像数组),迭代器能 “跳步”(it += 3);list是链表(节点零散分布),迭代器只能 “一步一步挪”(++it);- 有些迭代器只能 “读”(比如从文件读数据的迭代器),有些只能 “写”(比如向输出流写数据的迭代器)。
为了区分这些差异,STL 把迭代器分成了5 类,每类有明确的 “能力范围”(能做什么操作)。
3. STL 迭代器的 5 类(从弱到强排序)
| 迭代器类型 | 能力范围(能做什么) | 典型例子 | 类比:像哪种交通工具 |
|---|---|---|---|
| 输入迭代器 | 只能读元素,只能++(向前挪一步),不能写,不能--(向后)。 |
从文件读数据的迭代器 | 单向地铁(只能往前,不能回头) |
| 输出迭代器 | 只能写元素,只能++,不能读,不能--。 |
向文件写数据的迭代器 | 单向传送带(只能往前放东西) |
| 前向迭代器 | 能读能写,只能++(向前),不能--。 |
unordered_set的迭代器 |
共享单车(只能往前骑) |
| 双向迭代器 | 能读能写,能++(向前)也能--(向后),但不能跳步(it + 2不行)。 |
list、set的迭代器 |
自行车(能前进、后退,但不能飞) |
| 随机访问迭代器 | 能读能写,能++/--,还能跳步(it + n、it -= 3),支持比较(it1 < it2)。 |
vector、array的迭代器 |
汽车(能前进、后退、高速变道) |
关键点:后一类迭代器 “包含” 前一类的能力(比如随机访问迭代器也能++,和前向迭代器一样)。
在C++中使用标签类进行表示:
// 1. 最基础:输入迭代器标签(只能读、单向前进)
struct input_iterator_tag {};
// 2. 输出迭代器标签(只能写、单向前进)—— 注意:输出迭代器与输入迭代器是平行关系,不继承
struct output_iterator_tag {};
// 3. 前向迭代器标签(能读能写、单向前进)—— 继承输入迭代器(包含其能力)
struct forward_iterator_tag : public input_iterator_tag {};
// 4. 双向迭代器标签(能读能写、双向移动)—— 继承前向迭代器(包含其能力)
struct bidirectional_iterator_tag : public forward_iterator_tag {};
// 5. 随机访问迭代器标签(能跳步、比较)—— 继承双向迭代器(包含其能力)
struct random_access_iterator_tag : public bidirectional_iterator_tag {};二、再理解:什么是 traits?—— “迭代器的说明书”
模板函数怎么知道传入的迭代器是哪一类?从而选择合适的操作?
比如 STL 的advance(it, n)函数(功能:把迭代器it向前移动n步):
- 如果
it是随机访问迭代器(如vector的),最好直接it += n(高效); - 如果
it是双向迭代器(如list的),只能循环n次++it(没办法,只能这样)。
模板函数需要一个 “工具” 来查询迭代器的类型 —— 这个工具就是traits。
1. traits 的通俗理解:“产品说明书”
你买了一个 “迭代器”(比如vector的迭代器),它的 “说明书”(traits)上会写:
- 我是 “随机访问迭代器”(类型);
- 我指向的元素是
int(假设vector<int>); - ... 其他特性。
模板函数只要 “读说明书”(查 traits),就知道该怎么操作这个迭代器了。
2. STL 中的std::iterator_traits:标准 “说明书”
STL 已经帮我们做好了这个 “说明书工具”——std::iterator_traits(模板类)。它能提取迭代器的 3 个关键信息:
| 信息类型 | 作用 | 例子(vector<int>::iterator) |
|---|---|---|
value_type |
迭代器指向的元素类型(比如vector<int>的迭代器指向int) |
std::iterator_traits<it>::value_type → int |
iterator_category |
迭代器的类型(5 类中的哪一类) | → std::random_access_iterator_tag |
difference_type |
两个迭代器之间的距离类型(通常是ptrdiff_t) |
→ ptrdiff_t |
3. 用代码举例:查 “说明书”
#include <vector>
#include <list>
#include <iterator> // 包含iterator_traits
int main() {
// 1. vector的迭代器(随机访问)
auto vec_it = std::vector<int>().begin();
// 查元素类型:value_type
using vec_value = std::iterator_traits<decltype(vec_it)>::value_type; // int
// 查迭代器类型:category
using vec_cat = std::iterator_traits<decltype(vec_it)>::iterator_category;
// vec_cat 是 std::random_access_iterator_tag(随机访问标签)
// 2. list的迭代器(双向)
auto list_it = std::list<double>().begin();
using list_cat = std::iterator_traits<decltype(list_it)>::iterator_category;
// list_cat 是 std::bidirectional_iterator_tag(双向标签)
return 0;
}这里的random_access_iterator_tag、bidirectional_iterator_tag是 “标签类”(空类,只用来标识类型),就像说明书上的 “产品类型标签”。
4. 模板函数如何用 traits 做决策?
以advance函数为例,它靠 traits 查迭代器类型,然后 “因材施教”:
// 辅助函数1:处理随机访问迭代器(直接跳步)
void do_advance(std::random_access_iterator_tag) {
// 伪代码:it += n;
}
// 辅助函数2:处理双向迭代器(循环挪步)
void do_advance(std::bidirectional_iterator_tag) {
// 伪代码:for (int i=0; i<n; ++i) ++it;
}
// 对外接口:用traits查类型,再调用对应辅助函数
template<typename It>
void advance(It& it, int n) {
// 查迭代器类型(读说明书)
using Tag = std::iterator_traits<It>::iterator_category;
// 根据类型调用不同实现
do_advance(it, n, Tag());
}当你传vector的迭代器时,Tag是random_access_iterator_tag,调用 “跳步” 版;传list的迭代器时,Tag是bidirectional_iterator_tag,调用 “循环挪步” 版。
三、自定义traits步骤说明
步骤 1:定义 “默认 traits 模板”(处理一般情况)
模板类中定义要查询的 “类型信息”(比如is_arithmetic表示 “是否为算术类型”),并给出默认值。
// 自定义traits:判断类型是否为算术类型(int、double等)
template<typename T>
struct is_arithmetic_traits {
static const bool value = false; // 默认:不是算术类型
};步骤 2:为特定类型 “特化” traits(处理特殊情况)
// 特化:int是算术类型
template<>
struct is_arithmetic_traits<int> {
static const bool value = true;
};
// 特化:double是算术类型
template<>
struct is_arithmetic_traits<double> {
static const bool value = true;
};
// 特化:指针不是算术类型(保持默认false,可省略)
template<typename T>
struct is_arithmetic_traits<T*> {
static const bool value = false;
};步骤 3:使用自定义 traits 查询类型信息
在模板函数中通过traits::value获取类型特性,实现不同逻辑。
// 用自定义traits判断并执行不同操作
template<typename T>
void print_type_info(T x) {
if (is_arithmetic_traits<T>::value) {
std::cout << "这是算术类型,值为:" << x << std::endl;
} else {
std::cout << "这不是算术类型" << std::endl;
}
}
// 测试
int main() {
int a = 10;
double b = 3.14;
int* p = &a;
std::string s = "hello";
print_type_info(a); // 算术类型(int特化)
print_type_info(b); // 算术类型(double特化)
print_type_info(p); // 非算术类型(指针特化)
print_type_info(s); // 非算术类型(默认)
return 0;
}自定义 traits 的扩展:不止于 “布尔值”
traits 还能返回 “类型”(不止bool)。例如,定义一个返回 “类型对应的常量类型” 的 traits:
// 自定义traits:返回T对应的const类型(如int→const int)
template<typename T>
struct add_const_traits {
using type = T; // 默认:不添加const
};
// 特化:为非const类型添加const
template<typename T>
struct add_const_traits<T> {
using type = const T; // 如T=int → type=const int
};
// 使用:获取const类型
template<typename T>
void func() {
typename add_const_traits<T>::type x; // x的类型是const T
}
int main() {
func<int>(); // x的类型是const int
return 0;
}对于指针类型,需要特殊处理。
在 STL 的 traits 机制中,对指针类型(如int*、double*等原生指针)进行特殊处理,核心原因是:指针不是类类型(没有成员变量 / 函数),但却经常被当作 “迭代器” 使用(比如遍历数组)。为了让指针能像迭代器一样被 traits 识别和处理,必须通过 “模板特化” 为指针定制 traits 逻辑。
在 C++ 中,原生指针(如int\*)天然具备类似随机访问迭代器的能力:
- 可以用
++/--移动(p++指向后一个元素); - 可以用
+n/-n跳步(p + 3指向第 3 个元素); - 可以用
*p访问元素; - 可以用
</>比较位置(p1 < p2判断前后)。
例如,遍历一个数组时,int*完全可以当作 “迭代器” 使用:
int arr[5] = {1,2,3,4,5};
int* begin = arr; // 类似begin()
int* end = arr + 5; // 类似end()
for (int* p = begin; p != end; ++p) { // 用指针遍历,和迭代器用法一致
std::cout << *p << " ";
}STL 的算法(如std::sort、std::find)为了同时支持 “容器迭代器” 和 “原生指针”(数组场景),必须让 traits 能同时识别这两种类型。
traits(如std::iterator_traits)的默认实现是通过访问类的内部类型来获取信息的。例如,对于容器的迭代器(类类型):
// 容器迭代器的典型实现(类类型)
template<typename T>
class VectorIterator {
public:
using value_type = T; // 迭代器指向的元素类型
using iterator_category = std::random_access_iterator_tag; // 迭代器类型标签
// ... 其他成员类型
};
// traits的默认实现(针对类类型迭代器)
template<typename It>
struct iterator_traits {
using value_type = typename It::value_type; // 提取迭代器的value_type
using iterator_category = typename It::iterator_category; // 提取标签
};但指针是原生类型(不是类),没有value_type或iterator_category这样的成员类型。如果直接用默认的 traits 处理指针:
int* p;
using T = iterator_traits<int*>::value_type; // 错误!int*没有value_type成员编译器会报错 —— 因为它试图访问int*的value_type成员,而指针根本没有成员。
解决方式是对traits特化。
为了让指针能被 traits 识别,STL 对iterator_traits进行了指针版本的特化,手动为指针 “补充” 必要的类型信息:
// 对指针的特化版本(关键!)
template<typename T>
struct iterator_traits<T*> { // 专门处理T*类型
using value_type = T; // 指针T*指向的元素类型是T(如int*的value_type是int)
using iterator_category = std::random_access_iterator_tag; // 指针是随机访问迭代器
using difference_type = std::ptrdiff_t; // 两个指针的距离类型
using pointer = T*;
using reference = T&;
};
// 对const指针的特化(如const int*)
template<typename T>
struct iterator_traits<const T*> {
using value_type = T; // 注意:const int*的value_type是int(不是const int)
using iterator_category = std::random_access_iterator_tag;
// ... 其他类型
};有了指针的 traits 特化后,指针就能像迭代器一样被 STL 算法处理:
#include <algorithm> // 包含std::sort
int main() {
int arr[5] = {3,1,4,2,5};
// 用std::sort排序数组(传入指针,当作迭代器)
std::sort(arr, arr + 5); // 等价于sort(begin, end)
// 原理:sort内部通过traits获取指针的信息
// 1. 指针的iterator_category是random_access_iterator_tag,所以用高效的排序算法
// 2. 指针的value_type是int,所以知道要比较int类型
return 0;
}如果没有指针的特化,std::sort就无法处理数组(因为无法识别int*的特性),这会极大限制 STL 的通用性 —— 毕竟数组是 C++ 中最基础的数据结构之一。
四、总结:迭代器分类和 traits 的关系
- 迭代器分类:给不同 “能力” 的迭代器贴标签(比如 “随机访问”“双向”),明确它们能做什么操作;
- traits:一个 “查标签” 的工具(像读说明书),让模板函数能在编译时知道迭代器的类型;
- 最终目的:让模板函数(如
advance)能根据迭代器的 “能力” 选择最优实现,既通用又高效。
条款 48:认识 template 元编程(Template metaprogramming)。
一、先搞懂:什么是模板元编程(TMP)?
简单说,TMP 就是 “让编译器在编译期做计算” 的技术。
- 传统代码(如
int a = 3 + 5;)在运行时计算3+5; - TMP 代码能让
3+5在编译期就计算出结果(编译器直接生成a=8)。
你可以把 TMP 想象成 “编译器级别的计算器”:在代码编译时,编译器不仅检查语法,还会像 “程序” 一样执行 TMP 代码,算出结果后再生成最终的二进制文件。
二、TMP 的 “Hello World”:编译期计算阶乘
1. 传统运行时计算
用一个简单例子理解 TMP 的工作方式 —— 计算5!(5 的阶乘):
int factorial(int n) {
int result = 1;
for (int i = 2; i <= n; ++i) {
result *= i;
}
return result;
}
int main() {
int x = factorial(5); // 运行时计算5! = 120
return 0;
}2. TMP 编译期计算
// 模板元函数:编译期计算n的阶乘
template<int n>
struct Factorial {
static const int value = n * Factorial<n-1>::value; // 递归计算
};
// 特化:终止条件(0! = 1)
template<>
struct Factorial<0> {
static const int value = 1;
};
int main() {
int x = Factorial<5>::value; // 编译期计算5! = 120,直接生成x=120
return 0;
}关键差异:
- 运行时计算:程序运行时才循环计算,有执行开销;
- TMP 编译期计算:编译器在编译时就递归展开
Factorial<5>,直接得到120,运行时无需任何计算(相当于int x = 120;)。
三、TMP 能做什么?—— 3 个核心应用场景
TMP 的能力远不止 “编译期计算数字”,它本质是 “编译期的类型操作引擎”,主要用于:
1. 编译期常量计算
像上面的阶乘例子,还可以计算斐波那契数、数组大小等,完全消除运行时开销。
例如,编译期确定数组长度(避免硬编码):
template<int N>
struct ArraySize {
static const int value = N;
};
int main() {
int arr[ArraySize<10>::value]; // 编译期确定数组大小为10,等价于int arr[10];
return 0;
}2. 类型操作与转换
利用 TMP 在编译期处理类型,比如:
- 判断两个类型是否相同;
- 从 “类型列表” 中提取第 N 个类型;
- 给类型添加
const或指针修饰。
举例:判断两个类型是否相同(类似标准库的std::is_same):
// 默认:两个类型不同
template<typename T, typename U>
struct IsSame {
static const bool value = false;
};
// 特化:两个类型相同时
template<typename T>
struct IsSame<T, T> {
static const bool value = true;
};
int main() {
bool b1 = IsSame<int, int>::value; // true(编译期确定)
bool b2 = IsSame<int, double>::value; // false(编译期确定)
return 0;
}3. 代码优化与生成
TMP 能根据类型特性,在编译期自动生成最优化的代码(类似 “定制化代码生成器”)。
最经典的例子是 STL 的std::advance函数(之前讲过):
- 通过 TMP 的 traits 机制,在编译期判断迭代器类型;
- 自动生成 “随机访问迭代器用
it += n”“双向迭代器用循环++it” 等最优代码; - 运行时无需判断类型,直接执行最适合的逻辑。
四、TMP 的优缺点:为什么用?为什么慎用?
优点:
- 零运行时开销:计算和逻辑判断在编译期完成,运行时直接用结果;
- 更早发现错误:类型不匹配等问题在编译期暴露(而不是运行时崩溃);
- 代码高度复用:一套 TMP 代码可适配多种类型,自动生成定制化逻辑。
缺点:
- 编译时间长:TMP 代码需要编译器在编译期 “执行”,复杂逻辑会显著增加编译时间;
- 可读性差:模板递归、特化等语法比较晦涩,调试困难(错误信息冗长);
- 学习曲线陡:需要理解模板、特化、traits 等基础,才能写出实用的 TMP 代码。
五、TMP 在标准库中的应用
你可能已经在用 TMP 却没意识到,STL 中很多组件依赖 TMP:
std::iterator_traits:用 TMP 提取迭代器特性(条款 47);std::enable_if:用 TMP 在编译期选择函数重载(根据类型特性);std::type_info:部分功能依赖 TMP 的类型判断;- 数值算法优化:如
std::sin对整数参数的编译期优化。
六、初学者如何对待 TMP?
作为初学者,不必急于精通 TMP,但需要知道:
- TMP 是 “编译期的工具”:能做的事情很特殊(计算、类型操作),但不是所有场景都需要;
- 先会用,再学写:优先学会使用标准库中基于 TMP 的组件(如
std::is_same),再尝试自己实现简单 TMP; - 按需使用:当需要 “零运行时开销” 或 “编译期类型检查” 时,再考虑 TMP,否则优先用普通代码(可读性更重要)。
总结
条款 48 的核心是让你认识到:模板元编程(TMP)是一种在编译期执行的编程技术,能通过模板实现编译期计算、类型操作和代码优化。它的价值在于 “将运行时开销转移到编译期”,但代价是更高的编译时间和复杂度。
简单说,TMP 让编译器 “变聪明” 了 —— 不仅能检查代码,还能帮你 “提前算好结果”“定制代码”,最终让程序跑得更快、更安全。
章节总结
本章围绕 C++ 模板的核心特性与实践技巧展开,核心目标是帮助开发者写出灵活、高效且无隐患的泛型代码,关键要点可归纳为以下 4 类:
- 模板基础与语法陷阱
-
条款 32-33:使用typename标识嵌套依赖类型(如typename T::value_type),避免与变量名混淆;模板参数名需避免与外部作用域重名,防止歧义。
-
条款 34:模板函数重载时,优先通过 “模板特化” 而非 “重载非模板函数” 处理特殊类型,避免匹配优先级混乱。
-
模板类的设计与复用
-
条款 43:派生类模板访问基类模板成员时,需用this->或using声明显式引入(因编译器默认不查找模板基类成员)。
-
条款 44:将模板中与参数无关的代码(如通用算法)抽离到基类,避免因模板实例化导致的代码膨胀。
-
条款 45:用 “成员函数模板” 接受所有兼容类型(如shared_ptr
构造shared_ptr ),替代大量重载函数。 -
类型交互与运算
-
条款 46:模板类需支持混合类型运算(如Rational
* 2)时,将运算符重载为非成员函数并通过友元声明访问私有成员,确保左右操作数均能隐式转换。 -
条款 47:用traits类(如std::iterator_traits)在编译期提取类型特性(如迭代器类型、元素类型),结合迭代器标签的继承关系(input < forward < bidirectional < random_access)实现通用算法适配。
-
模板元编程(TMP)
-
条款 48:TMP 是编译期执行的编程范式,可实现编译期计算(如阶乘)、类型判断(如std::is_same)和代码生成(如根据迭代器类型选择最优算法),优点是零运行时开销,缺点是编译时间长、可读性低,适合底层库优化。
核心原则:泛型编程的关键是 “通用与高效并存”—— 通过模板实现代码复用,通过 traits 和 TMP 适配类型差异,同时规避语法陷阱与性能隐患。