我从零开始学 AI 应用开发:先搞清楚 AI 职业版图,再回答“我适不适合做 AI 应用开发”
我先说清楚:这篇里我讲的 AI,主要指“生成式 AI / 大模型(LLM)”相关工作(能聊天、能写代码、能做总结、能调用工具的那种)。它不等于所有机器学习,也不等于只能训练模型。后文里不额外声明时,“AI”都按这个语境理解。
我一开始以为“AI 相关工作”大概就是两种:要么训练模型,要么用 ChatGPT 写提示词。但当我真的想系统学习时,发现如果不先把“AI 职业有哪些类别、各自要什么能力、哪些能力是交叉的”弄清楚,很容易一上来就学偏:要么去啃模型训练细节,要么只练提示词却做不出能上线的东西。
所以这一篇我先不讲太多名词(RAG、Agent、MCP 都先放一边),只做两件事:
1) 给自己一张“AI 职业版图”的粗略地图 2) 再把“AI 应用开发工程师”放到地图上,讲清楚职责、优势、以及适合谁
1) 我把 AI 职业粗分成 6 类(先有地图,再选路线)
下面这个分类不是标准答案,只是我为了学习和选方向做的“可用版地图”。现实里会混在一起,但先分清有助于判断“我现在该学什么”。
先给一张“全景图”:技术层 → 职业映射(我用它来防止学偏)
说明一下:我以前在博客里用过 Mermaid,但有的平台/主题不会渲染 Mermaid。所以这里我先用“文字版全景图”,后续如果需要我会补一张真正的图片(用绘图工具导出 PNG)。
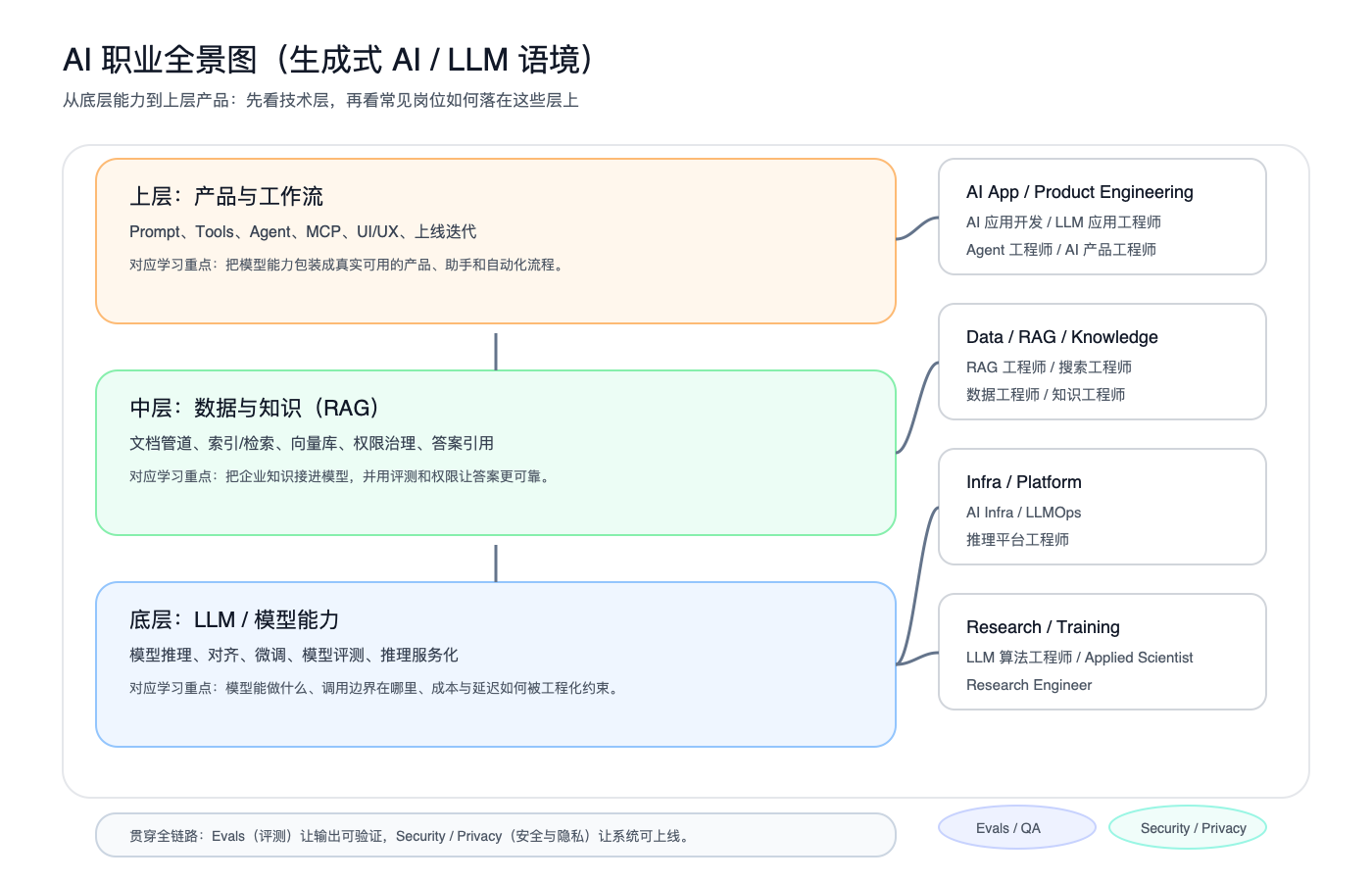
- 底层:LLM / 模型能力(推理、对齐、微调、模型评测)
- 对应职业:Research/Training(模型/算法)、Infra/Platform(推理/服务化)
- 中层:数据与知识(RAG、索引、向量库、文档管道、权限治理)
- 对应职业:Data/RAG/Knowledge(数据/知识)、Evals/QA(检索与答案质量评测)
- 上层:产品与工作流(Prompt、Tools、Agent、MCP、UI)
- 对应职业:AI App / Product Engineering(应用/产品工程)、Security/Privacy(权限与注入防护)
- 贯穿全链路:Evals(评测) + Security/Privacy(安全与合规)
A) 模型/算法类(Research/Training)
- 典型产出:模型训练、微调、推理优化、对齐、数据配方
- 核心能力:ML 基础、实验方法、分布式训练/推理、论文复现、评测
> 常见岗位叫法:LLM 算法工程师、NLP/多模态算法工程师、Applied Scientist、Research Engineer。
B) 平台/基础设施类(Infra/Platform)
- 典型产出:推理服务、GPU 调度、缓存、网关、监控、成本治理
- 核心能力:后端/分布式系统、性能/延迟、可靠性、SRE/可观测性
> 这类岗位在圈子里经常被叫做 AI Infra 工程师 / LLMOps / 推理平台工程师(不同公司叫法不一,但关注点很像)。
C) 数据/知识类(Data/RAG/Knowledge)
- 典型产出:数据管道、检索系统、向量库、文档处理、知识库问答
- 核心能力:数据工程、检索/排序、信息抽取、质量评估、治理与权限
> 常见岗位叫法:RAG 工程师、搜索/推荐工程师(偏检索侧)、数据工程师(偏管道侧)、知识工程师。
D) 应用/产品工程类(AI App / Product Engineering)
- 典型产出:对话产品、AI 助手、工作流/agent、工具集成、前后端体验
- 核心能力:API 调用与编排、提示词工程(作为工程的一部分)、产品体验、上线与迭代
> 常见岗位叫法:AI 应用开发工程师、LLM 应用工程师、Agent 工程师(偏工作流/工具)、AI 产品工程师。
E) 评测/质量类(Evals/QA)
- 典型产出:离线评测集、在线 A/B、自动化回归、幻觉/注入检测、基准体系
- 核心能力:评测方法、指标设计、实验设计、数据标注、观测闭环
> 常见岗位叫法:Evals 工程师、LLM 评测工程师、AI QA/质量工程师、数据标注/评审运营(偏数据侧)。
F) 安全/合规类(Security/Privacy/GRC)
- 典型产出:提示注入防护、权限模型、数据脱敏、审计、合规流程
- 核心能力:威胁建模、权限与隔离、审计与响应、供应链与依赖治理
> 常见岗位叫法:AI 安全工程师、应用安全工程师(AI 方向)、隐私/合规(GRC)与安全架构师。
哪些能力是交叉的?
不管你在哪一类,下面这些几乎都会用到,只是权重不同:
- 扎实的工程基础(前后端/后端更重要)
- 清晰的产品思维(用户到底要什么、怎么验证)
- 可观测性与迭代意识(能复盘、能优化、能对比)
- 安全与边界意识(把模型输出当不可信输入)
数学能力要不要?
我目前的结论是:要,但不一定一上来就要很深。
- 如果你走 Research/Training(模型/算法):数学(线代/概率/优化)基本是“吃饭的筷子”。
- 如果你走 Infra/Platform(AI Infra/LLMOps):更偏工程数学(性能建模、吞吐/延迟、成本与容量规划)。
- 如果你走 AI App(应用/产品工程):入门阶段更吃“工程 + 产品 + 迭代”,数学通常不是短板;但你仍然需要“会读指标、会做对比实验”的基本素养。
2) 那 AI 应用开发工程师具体在做什么?(职责、优势、适合谁)
主要职责(我现在的理解)
我把它总结成一句话:把模型能力变成“能在真实业务里运行”的产品能力。落到工程动作上,常见职责包括:
- 设计调用方式:消息/上下文怎么组织,输出怎么约束(结构化输出、格式校验)
- 把能力接进系统:接数据/检索、接工具/业务 API、做权限与审计
- 把体验做得像产品:流式输出、状态展示、错误分支、重试/取消
- 把系统做得可控:成本/延迟优化、缓存、限流、灰度、监控与日志
- 把质量做成闭环:评测、线上反馈、回放复盘、持续迭代
这个方向的优势(为什么我觉得适合从零入门)
- 更贴近“能做出东西”:你能更快做出可演示的 demo/作品集
- 工程路径更清晰:API、工具、RAG、评测、安全、部署,每一步都有可衡量的进展
- 更容易和业务闭环:你做的每个功能都能直接回答“对用户有啥用”
适合哪类人?
如果你符合下面几条,大概率会学得更顺:
- 有一点开发基础(前端/后端/全栈都行),愿意动手搭最小 demo
- 喜欢把“想法”变成“可用的小工具”,对产品体验有敏感度
- 能接受不确定性:同一输入可能输出不同,但你愿意用工程方法把它变可控
3) 我这一套自学系列怎么展开?(三期结构 + 下一篇预告)
为了避免“什么都想学 → 每天都在换名词”,我把自学拆成三期,每一期都围绕一个可交付的小成果:
第一期:入门(从 0 到跑起来)
- 目标:跑通最小调用 + 一个最小 Demo(能用、能复现、能定位错误)
第二期:基础(把输出变稳定、把数据接进来)
- 目标:结构化输出 + RAG 入门 + 基本评测/回归
第三期:提升(Agent/MCP/安全/部署)
- 目标:工具编排、授权边界、安全基线、可观测性、上线与成本治理
下一篇(第二篇)我才会进入细节:用一个 10 分钟能复现的 curl 实验,把“最小调用闭环”跑通,并把错误分支、日志字段、以及下一步如何接工具讲清楚。
6) 参考素材(我这一周挑的 3 条就够了)
我只保留最能支撑“入门闭环”的三条官方/权威资料,避免堆链接:
- OpenAI API Quickstart(先把最小调用跑通):https://platform.openai.com/docs/quickstart
- OpenAI Responses Guide(把对话/工具/结构化输出放进同一套调用模型里理解):https://platform.openai.com/docs/guides/responses
- OpenAI Tools Guide(理解“工具回合”:模型提调用、应用执行、结果回填):https://platform.openai.com/docs/guides/tools
小结
这篇我希望你最大的收获是:先有“AI 职业地图”,对我来说,“AI 应用开发工程师”是一条更容易做出可演示作品、也能逐步长到工程化与安全的路线。
为了避免写得太“概念味”,我给自己一个小约束:后面的每一篇尽量回答三个更具体的问题: 1) 我今天到底做了哪个小实验/小功能? 2) 它卡在哪里、我怎么定位的? 3) 这一步做完,我的下一步最小动作是什么?
// Kai@CodeHubble
// 观测坐标:AI 应用开发/2026-05-12